CSS Speech Module. El media 'speech' para la web hablada 21.9.15
En español el documento "CSS Speech Module" (sucesor de las Hojas de estilo auditivas de Css2.1) y las propiedades en él definidas. El paso del media="aural" al media="speech".
CSS Speech Module. El media 'speech' para la web hablada

Qué es el CSS Speech Module o los estilos para las páginas habladas
La presentación de la información auditiva es usada comúnmente por personas ciegas, con discapacidad visual o con problemas de lectura.
También hay ocasiones que se prefiere escuchar el contenido en vez de leerlo, incluso en ausencia de causas que impidan o dificulten leer.
La propuesta de la especificación lo define:
Las propiedades CSS definidas en el módulo del habla (CSS Speech Module) permiten a los autores controlar de forma declarativa la presentación de un documento en la versión auditiva.
El procesamiento auditivo de un documento combina la síntesis de voz (también conocido como "TTS", el acrónimo de "Text to Speech") y los iconos auditivos ("audio cues" en esta especificación).
Las propiedades CSS del habla proporcionan la capacidad de controlar el tono del habla y velocidad, el volumen, voces TTS utilizadas, etc.
Estas propiedades Css pueden ser utilizadas junto con las propiedades visuales (medios mixtos), o como una alternativa completa fonética a una presentación visual.
Estatus del CSS Speech Module
El documento "CSS Speech Module" pasó a ser "W3C Candidate Recommendation" el día 20 de Marzo de 2012.
Esto quiere decir que las modificaciones en la versión definitiva ("Recomendation" o especificación) serán mínimas.
Este módulo no sólo evoluciona las Hojas de estilo auditivas de Css2.1, sino que va un paso más allá al reemplazar el media="aural" en desuso (deprecated) en favor del media type "speech".
El modelo de caja del formato sonoro
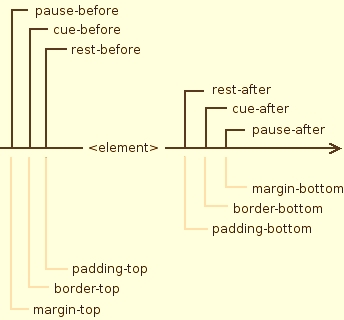 Al igual que otros media tienen su modelo de caja estándar, el medio hablado (Speech Module) también tiene la suya.
Al igual que otros media tienen su modelo de caja estándar, el medio hablado (Speech Module) también tiene la suya.
El siguiente diagrama muestra la equivalencia entre las propiedades de los modelos de cajas visuales y auditivas, aplicados a unelemento cualquiera.
El modelo de formato CSS para los medios auditivos se basa en una secuencia de sonidos y silencios que se producen dentro de un contexto anidado, similar al modelo de caja visual. Consta de dos canales (estéreo) en el espacio y una dimensión temporal (orden en el que se leen los elementos), en el que el habla sintética y las señales de audio coexisten.
El elemento seleccionado está rodeado por las propiedades "rest", "cue" y "pause" (equivalentes al padding, border y margin), y con los pseudo-elementos :before y :after se indica si se aplican antes o después del elemento.
Las propiedades Css del Módulo hablado
Voice-volume
Controla la amplitud de la onda de sonido generado por el sintetizador de voz, y también se utiliza para ajustar el nivel de volumen.
Valores posibles: silent | [[x-soft | soft | medium | loud | x-loud] || decibelio] y por defecto: medium.
Voice-balance
Controla la distribución espacial del sonido que se genera en un sistema de reproducción estéreo con dos altavoces (izquierda y derecha). Esto es, por dónde se escucha, si a la izquierda, centro o por la derecha de quien escucha.
Valores posible: número | left | center | right | leftwards | rightwards
El rango para "número" está entre -100 y 100, que equivalen a "left" y "right" respectivamente. El valor 0 (cero) = "center" es el valor por defecto.
Speak
Determina si se renderiza el texto o no (si se lee o no).
Valores posibles: auto | none | normal . Es el equivalente a display.
none: no se lee.
normal: Se lee, con independencia del valor de display y speak de su ancestro.
auto: Si "display: none" genera un valor de "none" (no se lee) y si es distinto computa como normal.
A tener presente que "display: none" en otros media en un elemento no puede ser anulado por ninguno de sus descendientes. Pero el valor auto para speak puede ser reemplazado por "none" o "normal".
Speak-as
Determina en qué forma se representa fonéticamente el texto, en base a una lista predefinida de posibilidades.
Valores posibles: normal | spell-out || digits || [ literal-punctuation | no-punctuation ].
normal: Utiliza las reglas de pronunciación para leer los elementos. Así, por ejemplo, los signos de puntuación no se leen, sino que se indican por la entonación y pausas.
spell-out: Se deletrea el texto. Indicado para acrónimos y abreviaturas
digits: Los números se leen uno a uno, no como cifras. Por ejemplo, 22 se oirá "dos dos".
literal-punctuation: Los signos de puntuación se leen.
no-punctuation: Al contrario, se omiten los signos de puntuación.
Pausas, silencios y descansos de la voz
pause, pause-before y pause-after
 Define la duración de la pausa antes o después de reproducir un elemento del texto. "Pause" es la forma acortada (shorthand) de las otras dos propiedades (pause-before y pause-after)
Define la duración de la pausa antes o después de reproducir un elemento del texto. "Pause" es la forma acortada (shorthand) de las otras dos propiedades (pause-before y pause-after)
Valores posibles: tiempo | none | x-weak | weak | medium | strong | x-strong.
tiempo: En unidades de tiempo absolutas (por ejemplo:1s)
none: No se hace ninguna pausa. Equivale a 0s.
x-weak, weak, medium, strong, and x-strong: Las pausas se logran por la ruptura o cambios en la pronunciación y acentuación. El tiempo exacto depende la la implementación.
h1 { pause: 20ms; } /* pause-before: 20ms; pause-after: 20ms */
h2 { pause: 30ms 40ms; } /* pause-before: 30ms; pause-after: 40ms */
h3 { pause-after: 10ms; } /* pause-before: sin especificar; pause-after: 10ms */
Rest, rest-before y rest-after
Los descansos hechos en la lectura hablada antes o después del elemento. Al igual que en la anterior propiedad, "rest" es la forma acortada de las otras dos.
Valores posibles: tiempo | none | x-weak | weak | medium | strong | x-strong
El significado es el mismo que en la propiedad "pause".
Cue: Clips o iconos de sonidos
Cue, cue-before, cue-after
El equivalente a los iconos gráficos. Son clips o archivos de sonidos pre-grabados o generados para reproducir antes o/y después del elemento. "Cue" es la forma acortada.
Valores posibles: (ruta) decibelios | none
h1 {
cue-before: url(../clips-1/pop.au) +6dB;
cue-after: url(../clips-2/pop.au) -3dB;
}
div.caution {
cue-before: url(./audio/caution.wav) +8dB;
cue-after: none;
}
Tipos de voces
Voice-family
 El equivalente a font-family. Indica el tipo de voz con el que se reproducirán los elementos. Puede ser una voz genérica por edad o género, o el nombre (similar al nombre de una tipografía).
El equivalente a font-family. Indica el tipo de voz con el que se reproducirán los elementos. Puede ser una voz genérica por edad o género, o el nombre (similar al nombre de una tipografía).
Los valores se pueden declarar por:
Género: "male", "female" y "neutral" los valores admitidos
Edad: "child", "young" y "old".
Nombre: Indicando el nombre de un archivo de voz.
preserve: Este valor como "hinerit" cuando se aplica al elemento raíz. Indica que el valor de 'voice-family' es el heredado y se utiliza independientemente de cualquier cambio que pueda haber en el etiquetado del contenido.
Número entero: Un entero indica la variante preferida (por ejemplo, "la segunda voz infantil masculina"). Sólo se permiten números enteros positivos (es decir, ni el cero ni negativos). El valor "1" se refiere a la primera de todas las voces coincidentes.
voice-rate
La propiedad voice-rate indica la velocidad del habla sintética generada en términos de palabras leídas por minuto.
Valores: [normal | x-slow | slow | medium | fast | x-fast] || porcentaje
Normal: La velocidad por defecto de la voz sintetizada. Este valor lo determina el tipo de voz y el programa utilizado, así como el idioma.
x-slow, slow, medium, fast, x-fast: muy lento, lento, medio, rápido o muy rápido. Depende del idioma.
Porcentaje %: Sólo con valor positivo. 100% igual a su elemento padre, si es menor más
lento y mayor a 100% se leerá más rápido.
voice-pitch
La propiedad "voice-pitch" indica el tono de la voz utilizada. Más grave o más aguda dentro de las posibilidades de la familia (Voice-family) elegida.
Valores: frequencia && absolute | [[x-low | low | medium | high | x-high] || [frequency | semitonos> | porcentaje]]
En el módulo hablado de Css (Speech Module) las palabras claves en los valores y los cambios relativos (frecuencia, semitono o el porcentaje) no se excluyen entre ellos.
voice-range
La propiedad "voice-range" indica la variación en el tono base. Un valor bajo produce una voz plana, monótona, mientras que cuanto más alto más animada.
Los valores posibles son los mismos de voice-pitch.
voice-stress
Define el énfasis con el que se genera la voz.
Valores: normal | strong | moderate | none | reduced
voice-duration
La propiedad voice-duration indica cuánto tiempo se debe tomar para renderizar el elemento seleccionado, sin incluir lo declarado para audio cues, pauses and rests. Excepto que se declare como "auto", tiene prioridad sobre "voice-rate".
Valores: auto | tiempo.
Estilos en elementos de listas y contadores
List-style-type
Esta propiedad define tres tipos de marcas para los elementos de las listas: glifos, marcas numéricas y alfabéticas.
Valores: disc, circle, square: dependerá de la aplicación el cómo las lea.
decimal, decimal-leading-zero, lower-roman, upper-roman, georgian, armenian Serán leídas tal como aparezcan y según el idioma y la programación de la aplicación. Por ejemplo: "Item uno", "item dos"
lower-latin, lower-alpha, upper-latin, upper-alpha, lower-greek: Se leen letra por letra según el idioma declarado en el documento: "alpha", "beta", "gamma", "a", "be", "ce"...
Elementos reemplazados y generados
content
La propiedad "content" es similar a la utilizada en otros media, como los medios impresos o de pantalla. Pero además de generar contenido si se utiliza con los pseudoelementos :before y :after se puede declarar en cualquier selector, en cuyo caso no genera, sino que sustituye al contenido de ese elemento.
ul#menu::before { content: "Comienza el menú de navegación: "; }
ul::after { content: "Fin del menú. "; }
Declarada en cualquier elemento, por ejemplo unas siglas, se leerá el contenido de la propiedad en vez de las siglas:
abbr {
content: attr(title);
}
<abbr title="Organización de Naciones Unidas">ONU</abbr>
En este último caso, el lector reemplazará la sigla ONU y leerá en su lugar lo indicado en el atributo title: "Organización de Naciones Unidas"
Pronunciación y fonemas
CSS no especifica la forma de definir la pronunciación (expresada mediante un alfabeto fonético bien definido) de una determinada pieza de texto dentro del documento marcado. Una propiedad "phonemes" se describía en los primeros borradores de esta especificación, pero se plantearon objeciones debido a la ruptura del principio de la separación entre contenido y presentación.
El atributo rel="pronunciation" permite importar diccionarios de pronunciación en los documentos HTML usando el elemento "link" (similar a como las hojas de estilo CSS se puede incluir).
Puedes consultar el documento (recomendación) "Pronunciation Lexicon Specification (PLS) Version 1.0"
Ejemplo de Css para ser hablado
El ejemplo siguiente de marcado html y sus estilos asociados para el media="speech" proviene del módulo del consorcio base de este artículo:
h1, h2, h3, h4, h5, h6 {
voice-family: paul;
voice-stress: moderate;
cue-before: url(../audio/ping.wav);
voice-volume: medium 6dB;
}
p.heidi {
voice-family: female;
voice-balance: left;
voice-pitch: high;
voice-volume: -6dB;
}
p.peter {
voice-family: male;
voice-balance: right;
voice-rate: fast;
}
span.special {
voice-volume: soft;
pause-after: strong;
}
...
<h1>I am Paul, and I speak headings.</h1>
<p class="heidi">Hello, I am Heidi.</p>
<p class="peter">
<span class="special">Can you hear me ?</span>
I am Peter.
</p>
Este ejemplo muestra cómo los autores pueden decirle al sintetizador de voz cómo hablar títulos HTML con una voz que llama "Paul", con un énfasis "moderado" (quel es más que normal) y la forma de insertar una señal de audio "cue" (clip pregrabado de audio situado en la URL indicada) antes del inicio de cada encabezado.
En un sistema de sonido estéreo los párrafos marcados con la clase CSS "Heidi" se prestan en el canal izquierdo de audio (y con una voz femenina, etc), mientras que la clase de "Peter" se corresponde con el canal derecho (y en voz masculina, etc.)
El nivel de volumen de los tramos de texto marcados con la clase "especial" es inferior a lo normal, y un límite prosódico se crea mediante la introducción de una pausa fuerte después de que se habla (nota cómo el span hereda la voz de la familia de su padre, el párrafo).
 y las propiedades en él definidas. El paso del media="aural" al media="speech".){kind=link}

Kseso
the obCSServer ᛯ Ramajero Argonauta, Enredique Amanuense de CSS.#impoCSSible inside
Dicen que, en español, EsCss es el mejor blog de CSS. Posíblemente exageren.
@Kseso EsCss Kseso
yo personalmente escucho muchos artículos largos en la web con la extensión en Chrome llamada "iSpeech", otra aplicación mejor es "Select and Speak - Texto a voz" pero resultaron cobrando...
ResponderEliminar